カテゴリー

【機械学習手法の総覧】手法13選の理解から実践までのガイド

機械学習は、データ駆動の時代において中心的な役割を果たしています。
日常の生活からビジネス、科学研究に至るまで、機械学習の技術は私たちの周りに数多く存在しています。
この記事では、機械学習の基本から応用までを網羅的に解説します。
この記事は以下のような方々に特におすすめです。
データサイエンスのキャリアを目指す方
既存の業務に機械学習を取り入れたいビジネスパーソン
研究や学問の領域で機械学習を活用したい研究者や学生
ITの領域でスキルアップを目指すエンジニア

目次
機械学習とは?

機械学習は、データ駆動のアプローチを使用して、アルゴリズムが経験を通じて改善する技術のことを指します。
この「経験」とは、大量のデータを指します。
機械学習は、人間が直接プログラムするのではなく、データを元に「学習」することで、タスクを自動的に遂行する能力を持つモデルを構築します。
機械学習の3つの主要な学習方法
機械学習は、コンピュータに特定のタスクを学習させるための技術の一つです。
この学習方法は大きく3つに分類され、それぞれの学習方法は、異なるタイプの問題やデータに適しています。
以下では、これらの学習方法の特徴や適用例、メリットとデメリットを詳しく解説します。
1.教師なし学習 (Unsupervised Learning)
教師なし学習は、正解ラベルが与えられていないデータセットを使用して、モデルを訓練します。
この方法では、アルゴリズムはデータの構造やパターンを探し出すことを目的としています。
- 適用例:顧客の購買履歴からの市場のセグメンテーション、類似の文書をグループ化するタスク、次元削減。
- メリット:ラベル付けが不要で、大量のデータを扱うことができる。
- デメリット:モデルの評価が難しい。結果の解釈が主観的になる場合がある。
2.教師あり学習 (Supervised Learning)
教師あり学習は、機械学習の最も一般的な形式です。
この方法では、アルゴリズムに入力データとそれに対応する正解ラベルが与えられます。
アルゴリズムは、このデータを使用して学習し、新しい未知のデータに対して予測を行います。
- 適用例:住宅の特徴から価格を予測するモデル、メールがスパムかどうかを判断するモデル、画像内の物体を識別するモデルなど。
- メリット:高い予測精度を持つモデルを構築できる。
- デメリット:十分な量の正解ラベル付きデータが必要。
3.強化学習 (Reinforcement Learning)
強化学習は、エージェントが環境と相互作用しながら、報酬を最大化するような行動を学習する方法です。
エージェントは、行動を選択することで環境の状態を変更し、その結果として報酬またはペナルティを受け取ります。
- 適用例:ゲームのプレイ、ロボットの動きの最適化、広告の最適な表示タイミングの決定など。
- メリット:環境との相互作用を通じて学習するため、実世界の複雑な問題に適用可能。
- デメリット:学習に時間がかかる場合がある。適切な報酬関数の設計が必要。
これらの学習方法は、それぞれ異なる特性や適用範囲を持っています。
問題の性質や利用可能なデータに応じて、最適な学習方法を選択することが重要です。
また、これらの方法を組み合わせて使用することで、さらに高い性能や効果を得ることも可能です。
ディープラーニングとの関係
ディープラーニングは、機械学習のサブセットとして位置づけられる技術です。
ディープラーニングは、多層のニューラルネットワークを使用して、複雑なタスクを解決するための技術として知られています。
特に、画像や音声のような非構造化データの解析において、ディープラーニングは非常に高い性能を発揮します。
しかし、機械学習とディープラーニングの間には明確な境界はありません。
ディープラーニングは、特定の種類の機械学習アルゴリズムを使用するものと言えます。
そのため、ディープラーニングを学ぶ前に、機械学習の基本的な概念を理解することが重要です。
機械学習は、データを元に予測や分類を行うための強力なツールとして、多くの産業や研究分野での利用が進んでいます。
特に、ビッグデータの時代において、機械学習はデータから価値を引き出すための鍵となる技術と言えるでしょう。
この技術を理解し、適切に活用することで、多くのビジネスや研究の課題を解決することが可能となります。

機械学習の手法13選比較一覧表【初心者・中級者に最適な手法がわかる】
| 手法 | 分類 | 難易度 |
|---|---|---|
| ロジスティック回帰 | 教師あり学習 | 中 |
| 決定木 | 教師あり学習 | 低 |
| ランダムフォレスト | 教師あり学習 | 中 |
| 勾配ブースティング木 | 教師あり学習 | 高 |
| サポートベクターマシン | 教師あり学習 | 高 |
| k-近傍法 | 教師あり学習 | 低 |
| ニューラルネットワーク | 教師あり学習 | 高 |
| 主成分分析 | 教師なし学習 | 中 |
| k-meansクラスタリング | 教師なし学習 | 低 |
| DBSCAN | 教師なし学習 | 中 |
| 階層的クラスタリング | 教師なし学習 | 中 |
| ガウス混合モデル | 教師なし学習 | 高 |
| Q学習 | 強化学習 | 中 |
機械学習の主要な手法とアルゴリズム13選を紹介

機械学習の手法は1つだけではありません。
特定のタイプのデータや問題に対して最適化されています。
以下に、主要な手法とアルゴリズムをいくつか紹介しますので参考にしてください。
教師あり学習の代表的な手法
教師あり学習は、入力データとそれに対応する正解ラベルを用いてモデルを学習する方法です。
以下では、教師あり学習の中で特に注目されている手法やアルゴリズムについて詳しく解説します。
1.線形回帰 (Linear Regression)
線形回帰は、データのトレンドを最もよく表す直線を見つける手法です。
連続値を予測する際に使用されます。
- 適用例:住宅価格の予測、売上予測。
- メリット:理解しやすく、計算コストが低い。
- デメリット:非線形のデータには適用が難しい。
2.ロジスティック回帰 (Logistic Regression)
ロジスティック回帰は、カテゴリカルな出力を予測するための手法です。
特に、二項分類問題に適用されます。
- 適用例:スパムメールの分類、顧客の購買確率の予測。
- メリット:出力が確率として解釈でき、高速に予測が可能。
- デメリット:非線形の境界を捉えるのが難しい。
3.決定木 (Decision Trees)
決定木は、データを分類するための木構造のモデルを構築する手法です。
各ノードで特徴の値に基づいて分岐し、最終的にリーフノードで予測を行います。
- 適用例:クレジット審査、病気の診断。
- メリット:可視化が容易で、データの前処理が少ない。
- デメリット:過学習しやすく、大きな木は解釈が難しい。
4.サポートベクターマシン (Support Vector Machines, SVM)
SVMは、データを高次元空間にマッピングし、最適な超平面(分離境界)を見つけることで、クラスを分離する分類器です。
クラス間のマージンを最大化することを目的とし、マージンは、超平面から最も近いトレーニングデータポイントまでの距離として定義されます。
カーネルトリックを使用して、非線形の分離境界も扱うことができます。
- 適用例:画像認識、テキスト分類、生物情報学での遺伝子分類、顔認識。
- メリット:高次元のデータでも効果的に動作し、カーネルトリックを使用することで、非線形の問題にも対応できます。
- デメリット:大量のデータに対しては、計算コストが高くなる可能性があり。
5.ランダムフォレスト (Random Forest)
ランダムフォレストは、複数の決定木を組み合わせて使用するアンサンブル学習の手法です。
各決定木は、データのサブセットと特徴のサブセットをランダムに選択して構築され、最終的な予測は、各決定木の予測を集約することで行われます。
その堅牢性と予測の正確さから、多くの実用的な問題に対して広く使用されています。
- 適用例:顧客の購買行動の予測、疾患の診断、金融取引の不正検出。
- メリット:過学習のリスクが低い。複数の決定木を組み合わせることで、モデルの汎化性能が向上。欠損値の取り扱いが容易であり、前処理が比較的簡単。
- デメリット:大量の決定木を構築するため、計算コストが高い場合があり。複雑なモデルであるため、結果の解釈が難しい。
6.ニューラルネットワーク (Neural Networks)
主に教師あり学習ですが、教師なし学習や強化学習のコンテキストでも使用されることがあります。
複数の層とノードから成る構造で、データの非線形な関係を捉える能力が高く、学習には大量のデータが必要。
- 適用例:画像認識、音声認識、自然言語処理、ゲームのAIなど、多岐にわたる領域での応用が見られる。
- メリット:非線形なデータの関係も捉えられる。深い層を持つモデルは高い表現力を持つ。複雑なタスクでも高い精度を達成。
- デメリット:学習に時間がかかる。過学習のリスクがある。モデルの解釈が難しい。適切なハイパーパラメータの選択が必要。
7.k-近傍法 (k-Nearest Neighbors, k-NN)
新しいデータ点に対して、最も近いk個のトレーニングデータ点を見つけ、それらの多数決や平均で予測を行います。
シンプルさと直感的なアプローチから、多くの初心者にとってアクセスしやすい手法として知られています。
- 適用例:画像認識、推薦システム、テキスト分類など、分類や回帰のタスクで使用される。
- メリット:モデルのトレーニングが不要。直感的で理解しやすい。非線形なデータにも適用可能。
- デメリット:量のデータに対して計算コストが高い。適切なkの選択や距離尺度が必要。次元の呪いに影響されやすい。
これらの手法は、それぞれ異なる特性や適用範囲を持っています。
問題の性質や利用可能なデータ、目的に応じて、最適な手法を選択することが重要です。
教師なし学習の代表的な手法
教師なし学習は、入力データのみを用いてモデルを学習する方法です。
正解ラベルが与えられないため、データの構造やパターンを探索します。
以下では、教師なし学習の中で特に注目されている手法やアルゴリズムについて詳しく解説します。
1.クラスタリング (Clustering)
クラスタリングは、データを似た特性を持つグループに分ける手法です。
データの隠れた構造やセグメントを発見するのに役立ちます。
- 適用例:顧客セグメンテーション、画像のグループ化。
- メリット:データの構造を発見できる。
- デメリット:最適なクラスタ数を決定するのが難しい。
2.次元削減 (Dimensionality Reduction)
次元削減は、データの特徴を圧縮し、低次元の空間にマッピングする手法です。
データの可視化やノイズの除去に役立ちます。
- 適用例:データの可視化、特徴選択。
- メリット:計算コストの削減、データの解釈性の向上。
- デメリット:情報の損失が発生する可能性がある。
3.連想ルール学習 (Association Rule Learning)
連想ルール学習は、データ内のアイテム間の関連性を探索する手法です。
特に、購買履歴の分析などに使用されます。
- 適用例:マーケットバスケット分析、商品の推薦。
- メリット:アイテム間の関連性を発見できる。
- デメリット:大量のデータを扱う場合、計算コストが高くなる。
これらの手法は、それぞれ異なる特性や適用範囲を持っています。
問題の性質や利用可能なデータ、目的に応じて、最適な手法を選択することが重要です。
強化学習の代表的な手法
強化学習は、エージェントが環境と相互作用しながら最適な行動を学習するための技術です。
以下では、強化学習の中で特に注目されている手法やアルゴリズムについて詳しく解説します。
1.Q学習 (Q-Learning)
Q学習は、行動価値関数を直接学習するオフポリシーのアルゴリズムです。
エージェントは、最適な行動を選択するためのQ値を更新しながら学習を進めます。
- 適用例:迷路の最短経路探索、ゲームのプレイ戦略の最適化。
- メリット:環境の動的な変化に柔軟に対応でき、過去の経験を再利用して学習が可能。
- デメリット:大規模な状態空間を持つ問題では学習に時間がかかる。
2.Deep Q Network (DQN)
DQNは、Q学習とディープラーニングを組み合わせた手法です。
ニューラルネットワークを使用してQ値を近似し、高次元の状態空間でも効率的に学習を進めることができます。
- 適用例:ビデオゲームの自動プレイ、ロボットの制御。
- メリット:高次元の状態空間でも効率的に学習が可能。
- デメリット:適切なハイパーパラメータの設定やネットワーク構造の選択が必要。
3.Policy Gradient (PG)
PGは、エージェントの方策自体を直接最適化する手法です。
方策をパラメトリックな関数で表現し、勾配上昇法を用いてパラメータを更新します。
- 適用例:連続的な行動空間を持つタスク、ロボットの動きの最適化。
- メリット:連続的な行動空間に適用可能で、方策の明示的な表現が得られる。
- デメリット:局所的な最適解に陥りやすい。
これらの手法は、それぞれ異なる特性や適用範囲を持っています。
問題の性質や利用可能なデータ、目的に応じて、最適な手法を選択することが重要です。
機械学習の手法を選ぶときのポイント
機械学習の手法を選択する際には、多くの要因を考慮しなければなりません。
適切な手法を選択することで、データの解析や予測の精度を向上させることができます。
以下に、手法を選択する際のポイントをいくつか紹介します。
チートシートを活用する
チートシートは、機械学習の手法やアルゴリズムを迅速に理解し、適切なものを選択するための便利なツールです。
機械学習の手法を選択する際の参考として、チートシートを活用することを推奨します。
scikit-learn
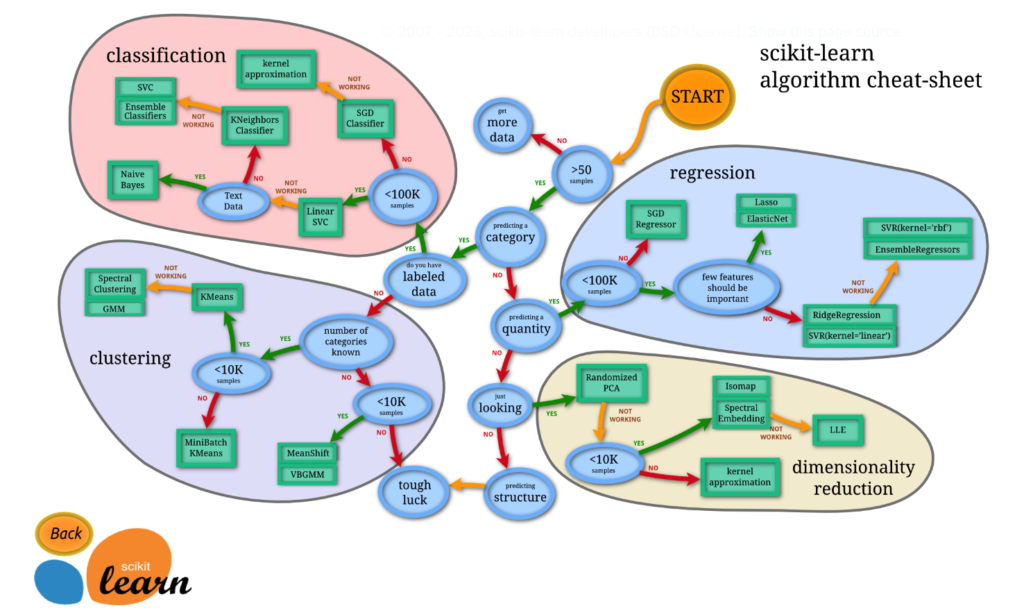
scikit-learnは、Pythonの機械学習ライブラリの一つで、多くのアルゴリズムが実装されています。
公式サイトには、手法の選択をサポートするチートシートが提供されており、初心者にも非常に役立ちます。
Azure Machine Learning

Azure Machine Learningは、Microsoftが提供するクラウドベースの機械学習サービスです。
このサービスには、機械学習の手法を選択するためのガイドが含まれています。
SAS Institute Japan

SASは、統計解析ソフトウェアのリーダーとして知られています。
SASもまた、機械学習の手法を選択するためのリソースを提供しています。
データの種類と利用目的に合わせる
機械学習の手法を選択する際には、データの種類や利用目的を考慮することが重要です。
例えば、教師あり学習、教師なし学習、強化学習など、機械学習にはさまざまな手法があります。
これらの手法は、それぞれ異なるデータの種類や利用目的に適しています。
計算時間と予測精度の高さを加味する
機械学習の手法を選択する際には、計算時間や予測精度も考慮する必要があります。
特に、大量のデータを扱う場合や、リアルタイムでの予測が求められる場合には、計算時間を最小限に抑えることが重要です。
また、予測精度の高さも、手法の選択において重要な要因となります。
実践!機械学習のモデル構築

機械学習のモデル構築は、単にアルゴリズムを適用するだけではなく、データの前処理から評価、そして最適化までの一連のプロセスを含む複雑なタスクです。
このセクションでは、実際にモデルを構築する際の詳細なステップとその注意点を解説します。
データの前処理
1.データのクリーニング
欠損値や外れ値を処理することで、データの品質を向上させます。
欠損値は平均値や中央値、最頻値で補完する方法や、欠損値を持つ行や列を削除する方法があります。
外れ値は、IQRやZスコアを使用して検出し、適切に処理します。
2.カテゴリ変数のエンコーディング
機械学習のアルゴリズムは数値データのみを扱うため、カテゴリ変数を数値に変換する必要があります。
ワンホットエンコーディングやラベルエンコーディングなどの方法があります。
3.データの正規化/標準化
データのスケールを揃えることで、アルゴリズムの収束速度を向上させることができます。
最小最大スケーリングやZスコア正規化などの方法があります。
フィーチャーエンジニアリング
1.特徴量の選択
関連性の低い特徴量や冗長な特徴量を削除することで、モデルの性能を向上させることができます。
相関行列や特徴量の重要度を使用して特徴量を選択します。
2.特徴量の生成
既存の特徴量を組み合わせて新しい特徴量を生成することで、モデルの予測性能を向上させることができます。
例えば、年齢と収入の2つの特徴量から、年齢ごとの平均収入という新しい特徴量を生成することができます。
モデルの訓練
1.データの分割
データセットを訓練データとテストデータに分割します。
訓練データはモデルの学習に使用し、テストデータはモデルの性能を評価するために使用します。
2.アルゴリズムの選択
問題の種類やデータの特性に応じて、適切な機械学習のアルゴリズムを選択します。
例えば、分類問題であればロジスティック回帰や決定木、回帰問題であれば線形回帰やランダムフォレストを選択することができます。
3.モデルの訓練
訓練データを使用してモデルのパラメータを学習させます。
この際、過学習を防ぐための正則化やドロップアウトなどのテクニックを使用することができます。
モデルの評価
1.評価指標の選択
問題の種類やビジネスの要件に応じて、適切な評価指標を選択します。
分類問題であれば精度や再現率、回帰問題であれば平均絶対誤差や平均二乗誤差を選択することができます。
2.モデルの評価
テストデータを使用してモデルの性能を評価します。
この際、交差検証やブートストラップサンプリングなどのテクニックを使用して、モデルの性能の信頼性を確認することができます。
モデルの最適化
1.ハイパーパラメータの調整
グリッドサーチやランダムサーチ、ベイズ最適化などのテクニックを使用して、モデルのハイパーパラメータを最適化します。
2.アンサンブル学習
複数のモデルの予測結果を組み合わせることで、モデルの性能を向上させるテクニックです。
バギングやブースティング、スタッキングなどの方法があります。
このように、機械学習のモデル構築は多くのステップを含む複雑なタスクです。
しかし、各ステップを適切に実行することで、高い性能を持つモデルを構築することができます。

まとめ

機械学習の手法やアルゴリズムは、日々進化しています。
しかし、その基本的な概念や手法は変わらず、データから学び、新しいデータに対して予測や分類を行うという点で一貫しています。
この記事を通じて、機械学習の基本的な概念や手法について理解いただけたでしょうか。
ぜひ、機械学習へと取り組んでみてください。

この記事の監修者

s
エンジニア・講師
山本 忠輝
東京大学大学院において宇宙関係の研究に従事。その後はIT開発の現場に身を置き、エンジニアとしての実務経験を積みながら、人事としての採用・育成にも携わる。現在は活学ITスクールの講師としても活動中。業界歴は14年におよび、現場と人事の両視点から未経験から活躍できるエンジニアを多数輩出。
この記事の監修者

s
谷川 昭雄
株式会社ラストデータ 代表取締役/元Earth Technology創業者
IT未経験者向け転職支援・エンジニア育成のプロ。
2013年に「英語×IT人材」に特化したEarth Technologyを創業し、年商18億円企業へと成長。2021年には株式会社ラストデータを設立。未経験から活躍できるエンジニアを多数輩出。累計5,000名以上のキャリア支援を行う。
IT業界歴は17年以上におよび、未経験者向け転職支援・エンジニア育成のプロ。
未経験からITエンジニアへ
転職成功者インタビュー







 お気軽にご相談ください。
お気軽にご相談ください。
